Autoscaling di GKE Pakai KEDA dan GCP Pub/Sub
Bikin worker pod di GKE auto-scale berdasarkan antrian Pub/Sub pakai KEDA. Dari 1 pod jadi 10 pod saat traffic tinggi, balik lagi saat sepi.
Pernah ngalamin worker yang kewalahan pas traffic mendadak naik, tapi idle banget pas lagi sepi? Nah, ini cerita tentang gimana bikin sistem yang bisa otomatis nyesuain jumlah pod berdasarkan seberapa panjang antrian pesan di Pub/Sub.
Masalahnya Apa?
Kalo kita punya worker yang jalan di Kubernetes, biasanya kita set jumlah pod secara manual. Tapi ini kurang efektif — terlalu banyak pod bikin boros, terlalu sedikit bikin antrian muncet. Yang kita mau itu pod nambah sendiri pas antrian panjang, dan berkurang sendiri pas antrian sudah kosong.
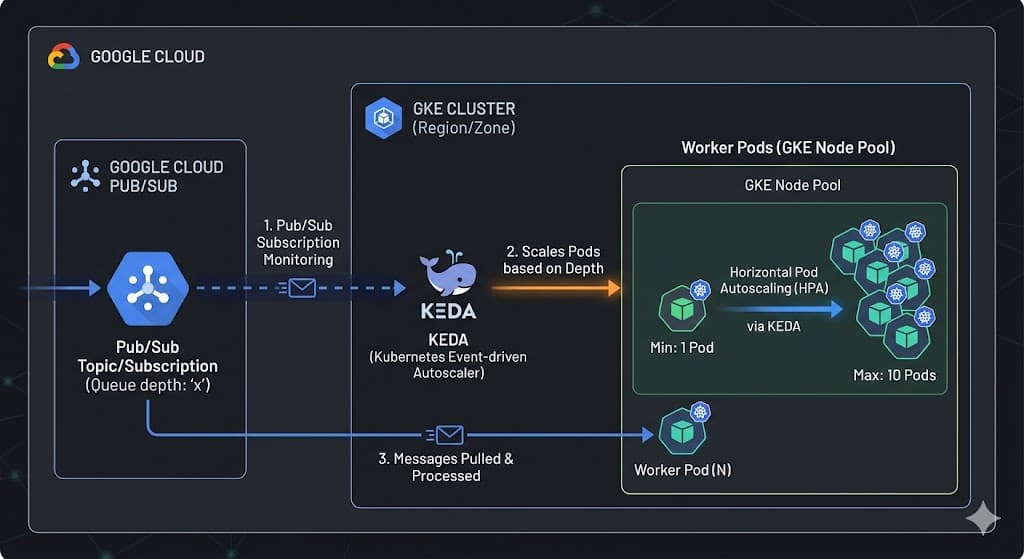
KEDA (Kubernetes Event-Driven Autoscaling) jawab masalah ini. Dia bisa lihat metrik dari luar cluster (di kasus ini, jumlah pesan di GCP Pub/Sub) lalu ngasih tahu Kubernetes buat nambah atau kurangi pod.
Arsitektur Singkat
Alur kerjanya gini:
- Pesan masuk ke Pub/Sub topic
- KEDA ngecek jumlah pesan yang belum diproses setiap 10 detik
- Setiap 50 pesan yang numpuk, KEDA nambah 1 pod worker (maksimal 10 pod)
- Pas antrian kosong, pod balik ke 1 aja setelah tunggu 60 detik
Semua infrastruktur dibangun pakai Terraform — mulai dari VPC, GKE cluster, Pub/Sub, sampe Service Account dan Workload Identity. Jadi bener-bener infrastructure as code.
Tantangan yang Dengernya Simple Tapi Nyebelin
Bikin cluster GKE yang private ternyata nggak sekadar centang "enable private nodes". Ada beberapa hal yang bikin makin ribet:
Zone yang keburu habis — Zone asia-southeast1-a nggak punya stok mesin e2-medium, jadi kita harus pakai zone b dan c aja. Ini baru ketemu setelah error dan cari tahu kenapa.
Organisasi melarang IP publik — GKE node nggak boleh punya IP publik karena kebijakan organisasi. Solusinya pakai Cloud NAT biar node tetap bisa keluar internet (buat pull image, dll) tanpa IP publik.
KEDA yang nggak mau jalan — Versi KEDA yang kita pakai awalnya (2.13.1) nggak kompatibel sama Kubernetes 1.35. ScaledObject dibikin, tapi HPA-nya nggak muncul. Setelah upgrade ke versi 2.17.0, baru deh jalan lancar.
Worker yang kecepatan ngolah pesan — Tanpa delay buatan, worker selesainya lebih cepat daripada KEDA ngatur scaling. Antrian kosong sebelum pod baru nyala. Makanya kita tambahin PROCESS_DELAY biar antrian sempat numpuk dan scaling-nya kelihatan.
Image Docker yang salah arsitektur — Laptop Mac pakai chip ARM, tapi node GKE pakai AMD64. Jadi pas build Docker, harus pakai --platform linux/amd64 biar image-nya bisa jalan di cluster.
Hasil Stress Test
Kita coba dengan beberapa skenario:
| Jumlah Pesan | Pod Maksimal | Pesan Gagal |
|---|---|---|
| 500 | ~4 pod | 0 |
| 2.000 | ~8 pod | 0 |
| 5.000 | 10 pod (maksimal) | 0 |
Pas test 5.000 pesan, antrian sempat mencapai 2.400 pesan perhitungan KEDA (48x ambang batas 50 pesan per pod). Pod langsung naik ke 10, memproses semua pesan, lalu turun balik ke 1 setelah antrian bersih. Waktu total proses sekitar 12 menit, dan scale-down berjalan gradual di 5 menit berikutnya.
Lesson Learned
- Selalu cek kapasitas zone sebelum bikin cluster — nggak semua zone punya stok mesin yang kita mau. Lebih baik tetapkan zone spesifik daripada_termasuk error di tengah jalan.
- KEDA itu sensitif sama versi Kubernetes — versi minor bisa bikin feature nggak jalan. Selalu cek compatibility matrix sebelum install.
- Workload Identity itu must-have buat GKE — nggak cuma buat security, tapi juga buat KEDA biar bisa baca metrik dari GCP tanpa service account key yang error-prone.
- Slow consumer* itu teknik testing yang *legit — biar autoscaling-nya kelihatan jelas, kadang kita harus sengaja bikin worker lambat. Di produksi, setting ini harus dihapus.
- Private cluster + Cloud NAT itu standar buat environment yang serius soal security. Node nggak perlu IP publik buat kerja.
Kesimpulan
KEDA sama GCP Pub/Sub terbukti bisa jadi solusi autoscaling yang reliable buat workload berbasis antrian di GKE. Sistemnya jalan sesuai harapan — pod scale up pas antrian panjang, scale down pas antrian kosong, dan nggak ada pesan yang gagal diproses.
Kuncinya ada di setup yang bener: Workload Identity buat autentikasi, Terraform buat infrastructure as code, dan testing yang memang disengaja buat trigger scaling.
Repo lengkap bisa dilihat di: https://github.com/stayrelevantid/aeroscale
Diskusi & Komentar
Bikin Dashboard Biaya Cloud Sendiri? Ternyata Bisa Gratis!
Next ArticleHari 1: Ngebangun SecureBank API dari Nol
Artikel Terkait
Hari 20: Terraform + Checkov, 15 Celah IaC Ketahuan
Bikin infrastructure as code pakai Terraform, lalu scan dengan Checkov. Hasilnya 15 celah keamanan ketahuan — S3 tanpa enkripsi, security group terbuka ke dunia.
Hari 35: Rego Policy Pertama — Wajib Resource Limits
Tulis Rego policy pertama untuk Gatekeeper: Pod/Deployment tanpa resource limits dan requests ditolak. 4 violation rules, enforcementAction deny, 0 violations.
Hari 21: Checkov vs Trivy IaC, Mana Lebih Jago?
Scan Terraform config dengan 2 tools: Checkov dan Trivy IaC. Hasilnya 15 vs 14 findings. Checkov lebih komprehensif, Trivy lebih praktis dengan severity level.